Contents
Training code abstraction with Trainer
Until now, I was implementing the training code in “primitive” way to explain what kind of operations are going on in deep learning training (※). However, the code can be written in much clean way using Trainer modules in Chainer.
※ Trainer modules are implemented from version 1.11, and some of the open source projects are implemented without Trainer. So it helps to understand these codes by knowing the training implementation without Trainer module as well.
Motivation for using Trainer
We can notice there are many “typical” operations widely used in machine learning, for example
- Iterating minibatch training, with minibatch sampled ramdomly
- Separate train data & validation data, validation is used only for checking the loss to prevent overfitting
- Output the log, save the trained model in regular interval
These operations are commonly applied, and Chainer provides these features in library level so that user don’t need to implement again and again. Trainer will mange the training code for you!
Details are also explained in official document of Trainer.
Source code with Trainer
Seeing is better than hearing, train_mnist_4_trainer.py is the source code which uses Trainer module. If I remove the comment, the source code looks like below,
from future import print_function
import argparse
import chainer
import chainer.functions as F
import chainer.links as L
from chainer import training
from chainer.training import extensions
from chainer import serializers
import mlp as mlp
def main():
parser = argparse.ArgumentParser(description=’Chainer example: MNIST’)
parser.add_argument(‘–batchsize’, ‘-b’, type=int, default=100,
help=’Number of images in each mini-batch’)
parser.add_argument(‘–epoch’, ‘-e’, type=int, default=20,
help=’Number of sweeps over the dataset to train’)
parser.add_argument(‘–gpu’, ‘-g’, type=int, default=-1,
help=’GPU ID (negative value indicates CPU)’)
parser.add_argument(‘–out’, ‘-o’, default=’result/4′,
help=’Directory to output the result’)
parser.add_argument(‘–resume’, ‘-r’, default=”,
help=’Resume the training from snapshot’)
parser.add_argument(‘–unit’, ‘-u’, type=int, default=50,
help=’Number of units’)
args = parser.parse_args()
from __future__ import print_function
import argparse
import chainer
import chainer.functions as F
import chainer.links as L
from chainer import training
from chainer.training import extensions
from chainer import serializers
import mlp as mlp
def main():
parser = argparse.ArgumentParser(description='Chainer example: MNIST')
parser.add_argument('--batchsize', '-b', type=int, default=100,
help='Number of images in each mini-batch')
parser.add_argument('--epoch', '-e', type=int, default=20,
help='Number of sweeps over the dataset to train')
parser.add_argument('--gpu', '-g', type=int, default=-1,
help='GPU ID (negative value indicates CPU)')
parser.add_argument('--out', '-o', default='result/4',
help='Directory to output the result')
parser.add_argument('--resume', '-r', default='',
help='Resume the training from snapshot')
parser.add_argument('--unit', '-u', type=int, default=50,
help='Number of units')
args = parser.parse_args()
print('GPU: {}'.format(args.gpu))
print('# unit: {}'.format(args.unit))
print('# Minibatch-size: {}'.format(args.batchsize))
print('# epoch: {}'.format(args.epoch))
print('')
model = mlp.MLP(args.unit, 10)
classifier_model = L.Classifier(model)
if args.gpu >= 0:
chainer.cuda.get_device(args.gpu).use() # Make a specified GPU current
classifier_model.to_gpu() # Copy the model to the GPU
optimizer = chainer.optimizers.Adam()
optimizer.setup(classifier_model)
train, test = chainer.datasets.get_mnist()
train_iter = chainer.iterators.SerialIterator(train, args.batchsize)
test_iter = chainer.iterators.SerialIterator(test, args.batchsize, repeat=False, shuffle=False)
updater = training.StandardUpdater(train_iter, optimizer, device=args.gpu)
trainer = training.Trainer(updater, (args.epoch, 'epoch'), out=args.out)
trainer.extend(extensions.Evaluator(test_iter, classifier_model, device=args.gpu))
trainer.extend(extensions.dump_graph('main/loss'))
trainer.extend(extensions.snapshot(), trigger=(1, 'epoch'))
trainer.extend(extensions.LogReport())
trainer.extend(extensions.PrintReport(
['epoch', 'main/loss', 'validation/main/loss',
'main/accuracy', 'validation/main/accuracy', 'elapsed_time']))
trainer.extend(extensions.ProgressBar())
if args.resume:
# Resume from a snapshot
serializers.load_npz(args.resume, trainer)
trainer.run()
serializers.save_npz('{}/mlp.model'.format(args.out), model)
if __name__ == '__main__':
main()
See how clean the code is! Compare above code and train_mnist_2_predictor_classifier.py. The code even does not contains for loop, as well as random permutation for minibatch, and save function explicitly.
The code length also become shorten almost half, even it supports more functionality than previous train_mnist_2_predictor_classifier.py code,
- Calculating validadtion loss, accuracy
- Save trainer snapshot in regular interval (it is including optimizer and model data.)
You can pause and resume training. - Print log in formatted way, together with the progress bar which showing training status.
- Output the training result to log file in json formatted text.
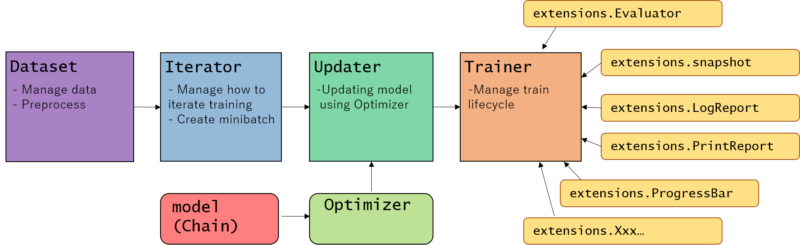
However it has changed much from previous code, user might not understand what’s going on. Several modules are used for together with the Trainer. Let’s see overview of the role for each module one by one.
- Dataset
- Interator
- Updater
- Trainer
- extensions
– Evaluator
– LogReport
– PrintReport
– ProgressBar
– snapshot
– dump_graph
- extensions
More detail functionality and usage are explained later.
Dataset
Input data should be prepared in Dataset format so that Iterator can handle.
In this example, dataset does not explicitly appear but already prepared
train, test = chainer.datasets.get_mnist()
This train and test is TupleDataset. Recall MNIST dataset introduction.
There are several Dataset classes, TupleDataset, ImageDataset etc and even you can define your custom Dataset class by using DatasetMixin.
All the Dataset follows common rule that when data is Dataset instance data[i] points the i-th data.
Usually it consists of input data and target data (answer), where data[i][0] is the i-th input data, data[i][1] is the i-th target data. However, it can be only one element or even more than 2 elements depending on the problem.
Role: Used for preparing input value to provide index access of data. Specifically i-th data can be accessed by data[i], so that Iterator can handle.
See also official document
Iterator
For loop of training minibatch is replaced and managed by Iterator.
train_iter = chainer.iterators.SerialIterator(train, args.batchsize)
This one line provides almost same with following training loop,
# Learning loop
for epoch in six.moves.range(1, n_epoch + 1):
# training
<strong> perm = np.random.permutation(N)
for i in six.moves.range(0, N, batchsize):
x = chainer.Variable(xp.asarray(train[perm[i:i + batchsize]][0]))
t = chainer.Variable(xp.asarray(train[perm[i:i + batchsize]][1]))
</strong>
# Pass the loss function (Classifier defines it) and its arguments
optimizer.update(classifier_model, x, t)
and in the same way applies for validation (test) dataset,
test_iter = chainer.iterators.SerialIterator(test, args.batchsize, repeat=False, shuffle=False)
is for
for i in six.moves.range(0, N_test, batchsize):
index = np.asarray(list(range(i, i + batchsize)))
x = chainer.Variable(xp.asarray(test[index][0]), volatile='on')
t = chainer.Variable(xp.asarray(test[index][1]), volatile='on')
loss = classifier_model(x, t)
minibatch random sampling, implemented by np.permutation can be replaced by just setting shuffle flag to True or False (default True).
Currently 2 Iterator classes are provided,
SerialIteratoris the most basic class.MultiProcessIteratorprovides multi process data preparation support in background.
Both of them have the
Role: Construct minibatch from Dataset (including background preparation support using multi process), and pass it to Updater.
See also official document
Updater
After creating Iterator, it is set to Updater together with optmizer,
updater = training.StandardUpdater(train_iter, optimizer, device=args.gpu)
Updater is in charge of calling optimizer’s update function, which means it corresponds to call
# Pass the loss function (Classifier defines it) and its arguments
optimizer.update(classifier_model, x, t)
Currently 2 Updater classes are (and 1 Updater will be) provided,
StandardUpdateris the basic class.ParallelUpdateris for utilizing multiple GPU at the same time.
Role: Receiving minibatch from Iterator, calculate loss and call optimizer’s update.
Currently I could not find official document for Updater, but you can refer source code docstring,
Trainer
Finally, Trainer instance can be created via Updater
trainer = training.Trainer(updater, (args.epoch, 'epoch'), out=args.out)
to start training, just call run
trainer.run()
Usually extensions are registered before start calling run of trainer, see below
Role: Manages Training lifecycle. extension can be registered.
Trainer extension
Trainer extension can be registered by trainer.extend() function.
These extensions are used in this example,
- Evaluator
Calculate Validation loss and accuracy, and it is printed out and logged to file. - LogReport
Print outlogfile in json format, in the directory specified byoutargument intrainer. - PrintReport
Print out log in standard out (console) to show training status. - ProgressBar
Show progress bar to show current progress of training. - snapshot
Save the trainer state (including model, optimizer information) in regular interval.
By setting this extension, you can pause and resume training. - dump_graph
dumps neural network computational graph
Role: hook trigger to trainer to do several events in specific timing
Trainer architecture summary
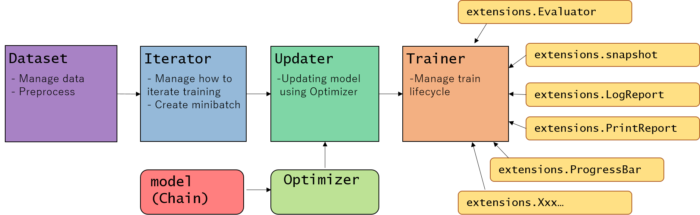
Refer above figure for the training abstraction procedure using Trainer module.
Advantage of using Trainer module
– Multi process data preparation using MultiProcessIterator
Python has GIL feature, so even you use multi-thread its threads are not executed in “parallel”. If the code contains heavy data preprocessing (e.g. data augmentation, adding noise before feeding as input) you can get benefit by using MultiProcessIterator.
– Multiple GPU utilization
– ParallelUpdater or MultiProcessParallelUpdater
– Trainer extensions are useful and reusable once you made your own extension
– PrintReport
– ProgressBar
– LogReport
— The log is in json format, it is easy to load and plot learning curve graph etc.
– snapshot
etc etc… Why don’t we use it!
Next: MNIST inference code