At the end of last year, I made a post like this:
https://twitter.com/corochann/status/1729863221748912427
“LLM+Search is Hot Lately: Chess, Shogi, and Go have seen computers surpassing humans through extensive evaluation and search driven by learning. With the compass of LLM, we can now explore intellectual spaces rather than just games. It’s exciting to see what discoveries lie ahead.”
There have been rumors circulating about a project at OpenAI referred to as “Q*,” quietly progressing behind the scenes. As reading material, the following sources caught my attention:
- Speculations on Q*
- Reinforcement Learning in the LLM Era
- Unveiling the Mystery of OpenAI’s Project “Q*”: Questions, Anxieties, and Hints
Recently, Google Deepmind published papers on “FunSearch” and “AlphaGeometry,” but there is potential for LLM+Search to be even more versatile and produce impactful results in this direction in the future.
So, what exactly does using LLM for search entail, and what are the recent trends in papers on this topic? Let’s explore that.
Contents
Breaking Down Tasks to Reach the Correct Answer
The first three papers I will introduce are more about breaking down thought processes rather than pure search. By properly breaking down the path to reaching a goal into steps and considering each one, we can improve the accuracy of arriving at the correct answer.
CoT: Chain of Thought
“Chain-of-Thought Prompting Elicits Reasoning in Large Language Models”
https://arxiv.org/abs/2201.11903
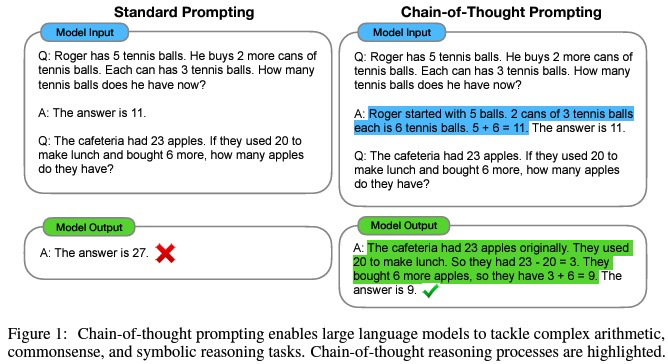
This paper demonstrates an improvement in answer accuracy by including the thought process leading to the answer when providing a few-shot example as a prompt. It is easier to understand by looking at concrete examples in the figure above. Rather than answering directly in one shot, including the intermediate steps in thinking and actually outputting the thought process allows us to reach the correct answer.
As a derivative, there is also something called Zero-shot-CoT.
“Large Language Models are Zero-Shot Reasoners”
https://arxiv.org/abs/2205.11916
In this case, the prompt is simpler, with just the phrase “Let’s think step by step.” This significantly improves answer accuracy and is very easy to use. This paper has been widely cited.

Similar to the original CoT, LLM can break down and think through the task according to the problem, even without including a few-shot example, simply by including the sentence “Let’s think step by step.” This approach leads to reaching the correct answer.
ReAct: Reasoning and Action
“ReAct: Synergizing Reasoning and Acting in Language Models”
https://arxiv.org/abs/2210.03629
https://react-lm.github.io/
CoT focused solely on reasoning, while ReAct has improved its performance by incorporating “action“. For example web search action (more specifically, searching related text from Wikipedia and using it as input to complement LLM) is used in this paper.

AutoGPT
https://news.agpt.co/
https://github.com/Significant-Gravitas/AutoGPT
Succeeding from ReAct, AutoGPT is a tool designed to automate various tasks.
For example, a website is created in just three minutes without writing any code in below demo.
LLM + Search: Utilizing LLM Recursively for Exploration
Here we come to the main topic of this article is research that achieves optimization for a goal by recursively utilizing LLM for exploration.
Voyager
“Voyager: An Open-Ended Embodied Agent with Large Language Models”
https://voyager.minedojo.org/
https://arxiv.org/abs/2305.16291
https://github.com/MineDojo/Voyager
As an example of Open World Search using LLM, Voyager takes on the challenge of Minecraft.
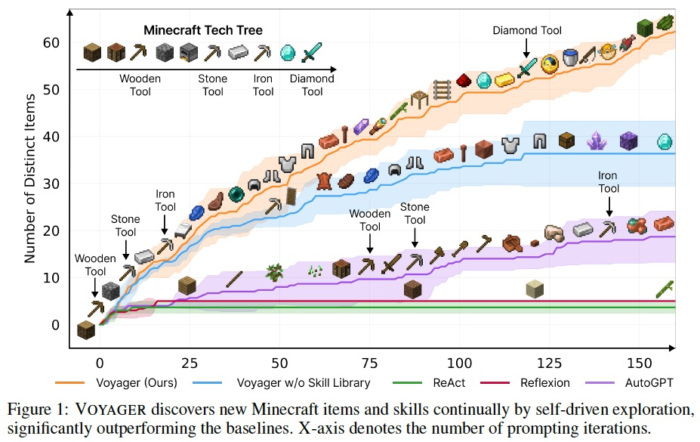
It achieves better performance compared to the aforementioned ReAct and AutoGPT by incorporating unique innovations such as:
- 1. Automatic Curriculum
- Determining the next sub tasks to solve. It considers new tasks that are not too difficult based on the current state. (LLM itself has some prior knowledge of Minecraft to some extent.)
- 2. Skill library
- Functions of code, like equipping a sword and shield to defeat a zombie “combatZombie”, are encapsulated into skills and registered in a Skill Library. This allows them to be referenced and called upon later. By doing so, it is possible to reuse complex actions that have been successful in the past.
- Skill Library references use embeddings based on the description text of this function, similar to RAG.
- 3. Iterative prompting mechanism
- Considering the current environmental state and code execution errors to determine the next actions or modifications.

In this paper, the focus is on evaluating LLM’s ability for Open World Search. Instead of using image inputs or raw controller commands, it interacts with Minecraft through its API to obtain the current state and perform actions.
Utilizing LLM for exploration is demonstrated below,
- By executing various code segments from LLM and observing their behavior, desired actions or skills are acquired.
- Through the concept of the Skill Library, one can continually challenge more difficult tasks while incorporating their own growth.
While prior knowledge of Minecraft may have contributed to its success, the approach seems versatile and applicable to various tasks.
The following three papers are from DeepMind. In each case, LLM is used to search for outputs that increase the achievement score for tasks that can be quantitatively scored.
RestEM
“Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models”
https://arxiv.org/abs/2312.06585
Rest^EM is a technique that combines ReST (Reinforced Self-Training) with EM (Expectation Maximization).
It comprises two steps:
1. Generate (E-step): The language model generates multiple output samples for each input context. Then, we filter these samples using a binary reward to collect the training dataset.
2. Improve (M-step): The original language model is supervised fine-tuned on the training dataset from the previous Generate step. The fine-tuned model is then used in the next Generate step.
- E-step: In this step, LLM generates multiple candidate answers.
- M-step: Among the generated candidates, the ones with good performance are selected as data to improve LLM.

This paper demonstrates that the proposed method works well for tasks that can be quantitatively evaluated.
- MATH (Mathematical problem solving): Hendrycks’ MATH dataset
- APPS (Code Generation): APPS (Introductory) dataset.
While the E-step uses the updated LLM, the M-step fine-tunes it from Pretrained weights each time. Overfitting appears to be a potential issue in this approach.
FunSearch
“Mathematical discoveries from program search with large language models”
https://www.nature.com/articles/s41586-023-06924-6
https://deepmind.google/discover/blog/funsearch-making-new-discoveries-in-mathematical-sciences-using-large-language-models/
This paper from DeepMind, published in Nature, introduces FunSearch, short for Function space search. It employs LLM to search for better scores on challenging problems by seeking improved functions (solutions or algorithms). During the search, it uses an Evolutionary Algorithm to evolve and enhance algorithms while keeping the best-performing code alive.
The paper successfully finds better algorithms than existing heuristic algorithms for two problems: the cap set problem and online bin packing (and some others in appendix).
The overall mechanism involves using a pretrained LLM (Codey, specialized for code generation) to generate candidate solutions, evaluating their scores, and saving the best ones in a “Programs database”.
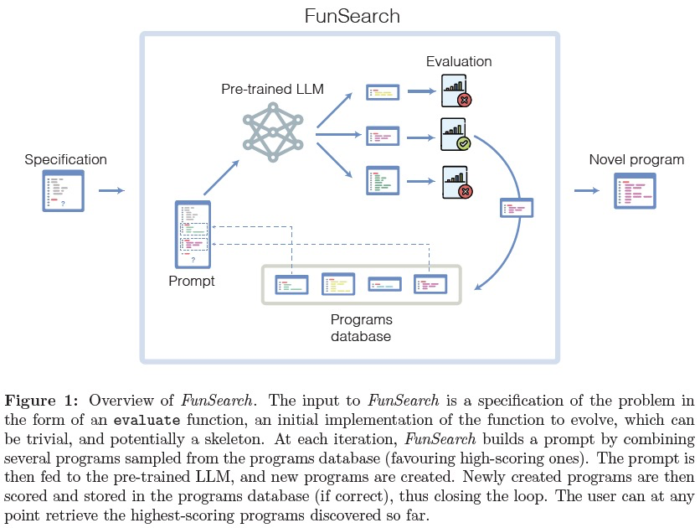
When generating the next set of candidates, an evolutionary algorithm is used to improve the solutions. This EA component seems to have a somewhat heuristic nature, and further improvements may be possible in the future.
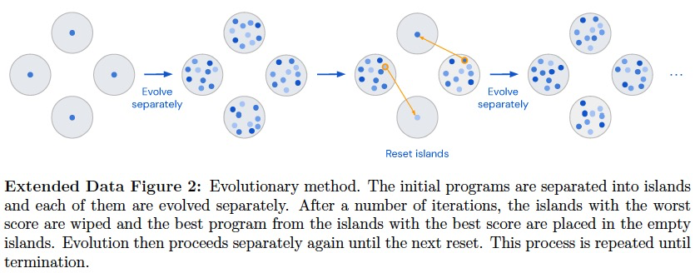
Instead of asking it to create code from scratch, it provides task-specific templates and focuses on the core aspects of heuristic algorithms (e.g., priority, heuristic below) for the given problem. This kind of domain knowledge may be still necessary.

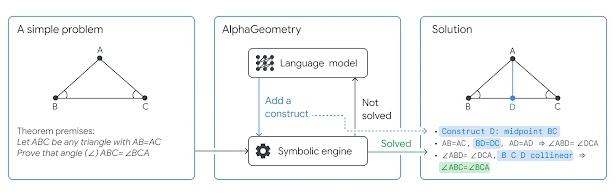
AlphaGeometry
“Solving olympiad geometry without human demonstrations”
https://deepmind.google/discover/blog/alphageometry-an-olympiad-level-ai-system-for-geometry/
https://github.com/google-deepmind/alphageometry
Another Nature paper from DeepMind, AlphaGeometry, shows that it was able to solve 25 out of 30 geometry problems in the International Mathematical Olympiad (IMO).
It employs a Neuro Symbolic approach, transforming geometry problems into symbols for machine processing. The language model used here was trained on a dedicated dataset of 100 million samples, suggesting that it was developed specifically for this task rather than starting from a generic LLM.
Conclusion
The use of LLM allows for the automatic decomposition of complex problems into smaller tasks (path breakdown) during examination [CoT]. It also enables actions such as retrieving information from external sources and observing changes [ReAct, AutoGPT, Voyager]. Knowledge gained during the search process can be retained and effectively utilized in the future as “Skills” [Voyager], and the output can be improved iteratively [FunSearch]. Results from the search process can serve as learning data, specializing LLM for the specific task [Rest^EM].
However, it’s worth noting that Rest^EM, FunSearch, and AlphaGeometry all assume the ability to quickly evaluate the quality (reward) of the output solution. As a result, they seem to be limited to mathematical and coding problems at this stage.
Using LLM has made it easier to handle tasks with non-standard inputs and outputs, suggesting that there are still many applications to consider in the realm of exploration. Exciting developments in this area are anticipated in the future.