
Preferred Networks was a place that helped me build my confidence as an engineer
I joined Preferred Networks in December 2016 and leaving after eight years of work. I’d like to take a look back at what I was involved in. For me, PFN ca...
I joined Preferred Networks in December 2016 and leaving after eight years of work. I’d like to take a look back at what I was involved in. For me, PFN ca...

Since the emergence of generative AI like LLM, the pace of publishing papers in the industry has accelerated so fast. I’m trying so hard to keep up. I sur...
The birth of ChatGPT is undoubtedly a technical breakthrough. Everyone surprised with its remarkably versatile responses across various domains. Some have even ...
At the end of last year, I made a post like this: https://twitter.com/corochann/status/1729863221748912427 “LLM+Search is Hot Lately: Chess, Shogi, and Go...
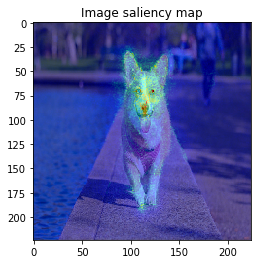
Japanese is available at Qiita. From left: 1. Classification saliency map visualization of VGG16, CNN model. 2. iris dataset feature importance calculation of M...
This post is based on the jupyter notebook ptb_dataset_introduction.ipynb uploaded on github. Penn Treebank dataset, known as PTB ...
So how to implement custom extensions for trainer in Chainer? There are mainly 3 approaches. Define function Use decorator, @chainer.training.extension.make_ext...
Predict code is pretty much the same with Predict code for simple sequence dataset, so I won’t explain in detail. Code The code is on the github, predict_p...

Long Short Term Memory Long short term memory is advanced version of RNN, which have “Cell” c to keep long term information. LSTM network Implementati...
This post mainly explains train_ptb.py, uploaded on github. We have already learned RNN and LSTM network architecture, let’s apply it t...